What's next for SRE tooling?
Most of the focus in SRE today is on firefighting with with better monitoring, observability, and incident response. As the industry moves forward, the focus will shift towards fire safety engineering, i.e. building resilient systems from the beginning, and preventing problems from happening in the first place.
Many teams out there are ahead of the curve, and are using load testing and chaos testing to ship more resilient systems and find zero MTTR issues. However, the problem is that all current tools for proactive testing fall short in a number of ways, and if the majority of the industry is to follow the early adopters and adopt proactive approaches themselves, we will need better tools.
tldr It’s time to start moving beyond just reacting, and it's time to build better tools.


"SRE tooling"? Why should we care?
SREs run (the software that runs) the world
For those not steeped in the world of production engineering, “SRE” stands for "site reliability engineering", and SREs are the people who keep production running.
"Production" is all the digital stuff we all use and rely on: from ordering food on DoorDash, to watching something on Netflix, and Googling “new netflix documentaries” beforehand. Amazon, TikTok, YouTube and every other production service that you can name needs SRE, as well as thousands of services that you don’t even know exist but power every aspect of our daily existence in the year 2022. Think routing & managing deliveries of physical goods, moving money around, running manufacturing, and running all sorts of various real-world infrastructure. “Software is eating the world”, clichéd as it might be, is true.
“SRE” is a relatively new term (and it’s a shame “production engineering” never really caught on beyond Facebook), and while the job has existed since the first software system went into production, the way we develop, operate and run software has evolved and the job of keeping that software running well has evolved in lockstep. SRE is the most recent flavor of it.
SRE can mean different things in different companies and industries, but the constants are:
- SREs are very difficult to hire. It’s a job that requires a rare blend of experience and the ability to move across domains, as well as the willingness to be on-call.
- SRE teams are often a bottleneck and create downward pressure on development velocity (not too dissimilar to security teams).
- SREs are often stressed, overworked and overstretched - stuff goes wrong all the time in large production systems.
- Production systems keep increasing in complexity and troubleshooting is getting harder
It's still the early days of SRE
The SRE book came out six years ago, but we’re far away from SRE being understood and “done” as a discipline, or from having a repeatable playbook for doing SRE.
Production systems at scale keep getting more complex, and outages and downtime are a regular occurrence, even for the best teams and products in the industry. (SRE Weekly lists several visible outages of well-known services in every issue).
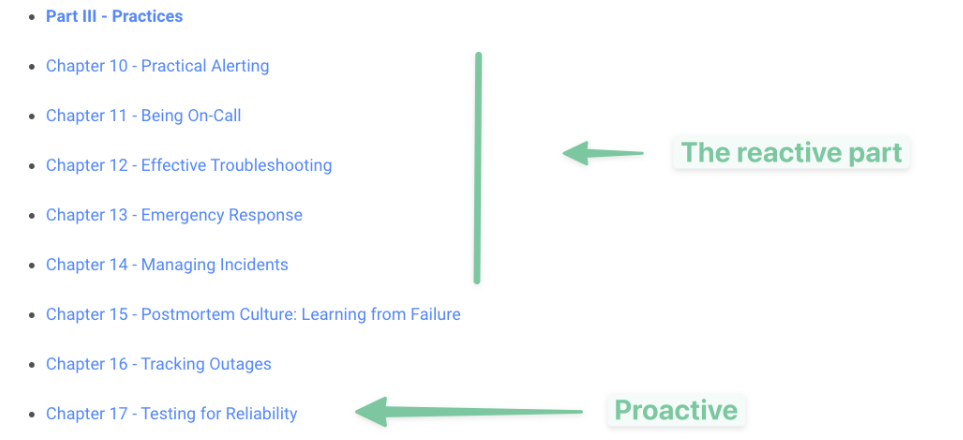
Most of us are in reactive land right now
Most SRE teams today are focused on figuring out the urgent & reactive part of what it takes to run a reliable & performant production system:
- Monitoring & observability
- Incident response & analysis
(Plus increasingly often there's a sprinkling of guardrails and contracts around performance & reliability on top with SLOs.)
That makes sense of course. The first thing to take care of in production is to be able to answer “what the heck is going on?”. You’ve got to make sure you will know when something goes wrong - that's your traditional infrastructure & service-level monitoring.
Once something has gone wrong, you lean on your observability stack to ask complex questions that you formulate on the fly as you dig into the issue.
Incident response is also obvious, because once you know something’s wrong you need a process to react to incidents, manage the investigation & troubleshooting process, get everything back up and running, and then capture what happened to analyze the incident and learn from it.
SLOs help with both (1) and (2) acting as both guardrails around reliability & performance expectations, a filter to help decide when an alert should actually page someone, and a way for SREs, developers and “business” to have a shared language.
Product landscape
If we map the list above to the product landscape, what do we see?
- Infra & application monitoring is very mature. You’re spoilt for choice with Datadog, AppDynamics, Prometheus/Grafana, New Relic, Sentry and so on. There’s also Honeycomb which is in a class of its own and IMO is one of a handful of really interesting new things in the space. (Another one is ebpf and products building on top of it.) Everything else is a slightly different take on what we've had for years.
- Incident response & analysis is a very busy space right now with a lot of innovation. You've got Transposit, Komodor, Incident, Shoreline, Kintaba, Rootly, FireHydrant, and Grafana On-Call (which has just been open-sourced) for incident response. You’ve got Fiberplane to help troubleshoot as an incident is happening. You've got Jeli which is focused specifically on post-incident learning. There's a ton of stuff in this space, and no obvious winner yet.
- SLOs - Nobl9 is a dedicated SLO platform, with Datadog, NewRelic and others offering ways to create and manage SLOs inside their monitoring products.
What lies beyond reactive land?
There’s much more we can do to help us run well-performing production systems than just reacting, and that’s what the most sophisticated teams are busy exploring & implementing today, and where the rest of the industry will find themselves in 2-3 years.
The next stage of evolution is adopting practices for improving performance & reliability proactively, i.e. proactive testing and experimentation.
It just so happens that the chapter on testing in The SRE Book immediately follows all of the reactive practices we looked at above. I don’t think it’s intentional, but it’s neat.

The “T” in SRE stands for “testing”
I'm totally stealing this from Sergei of AtomicJar/Testcontainers. Stealing it shamelessly because it's good. It's hilarious and it's true.
"T" in "DevOps" stands for "Testing".
— Sergei Egorov (@bsideup) March 15, 2021
(By the way if you’re not using Testcontainers already, you should be!)
The next step in the innovation in tools for SRE and Production Engineering needs to be in testing. But not the testing we typically think of of the unit testing, integration testing, and end-to-end testing kind, but testing of performance and reliability, from a whole-system perspective, and with a proactive approach.
Am I saying SREs don't test?
No, not at all. That would not be a true statement. Plenty of testing on services & infrastructure is done today by SRE teams (or sometimes by developers as part of production-readiness prep, which is usually managed by SRE). Typically it’s some combination of ad-hoc chaos testing and load / stress testing, with some form of synthetic testing sometimes thrown in.
The options in every category are numerous, with both open-source and proprietary offerings. The problem is not that we have no tools, the problem is that all existing tools leave a lot to be desired.
And by “a lot to be desired” I mean “not a combination of all of these”:
- Developer-first, with a focus on DX and easy onboarding
- Focused on applications rather than only infrastructure
- Cloud-native
- Can be offered as a part of an internal self-service platform
Let’s dig into what makes for a better tool
Let’s look at load testing, which is an area I’m very familiar with. Where do current offerings fall short exactly?
Consider this scenario: You’re on an SRE (or Platform) team, and your company is reaching a point where performance & reliability go from “nice to have”, to “absolutely critical”. You need to come up with a solution for load testing that can be used across the entire organization. Regardless of what some dev teams may already be using, or your personal preferences, this where you are going to find yourself:
- Hosted SaaS solutions don’t scale both from traffic generation and cost perspective and usually get ruled out very quickly. Every single offering out there today is priced as if it’s still 2010 - prohibitively expensive for testing frequently, and with complex pricing models based on the number of test minutes (ok…), number of virtual users (huh?) or virtual user concurrency (huh?!). Testing internal services is either outright impossible or hard and requires setting up custom agents or opening up firewalls/security groups.
- Open source solutions are free (but free as in “free puppy” rather than “free beer”) and in theory don’t limit you to the amount of traffic you can generate or whether you can test internal services, but are not cloud-native and require you to manage load testing infrastructure. They also tend to come with no UIs at all or very simplistic ones, which means that if you want to offer them as a self-service solution, you have to build that yourself.
What most teams end up doing is taking an open source project and spending time and effort to build their own internal load testing platform on top. (With some more foolhardy adventurous teams deciding to build their own from scratch, but these are far and few in between.)
I’ve seen a few of these internal platforms, and every single one does a decent job of solving the problem of spinning up and managing load testing infrastructure, but does little to offer good DX on top, and good DX is critical if you want developers to buy-in and actually run load tests themselves, as opposed to relying on you to do it for them. This is understandable - building tools is hard and time consuming, and time is a precious commodity if you’re an SRE/Platform engineer. Smart teams understand that, but have had little choice until recently.
Being able to run large-scale load tests through some sort of a self-service UI is just one piece of the puzzle though when it comes to making load testing better. There’s still a lot of work to be done to make it easy to create test scripts and test data, run those tests, and then answer the “so what?” question when faced with metrics generated by the load tests.
By the way, this is what we’re doing at Artillery right now. We are addressing all of those shortcomings to build the best load testing platform in the world. It’s open source, it’s cloud-native, and it’s built for developers and SREs and by developers and SREs. We just released open-source highly-distributed completely serverless load testing. Check it out!
It’s not just load testing
Existing chaos testing tools and synthetic testing tools suffer from very similar issues.
Synthetic testing is very similar to load testing in that it’s stuck somewhere around year 2016. We need something better than the likes of Pingdom, Datadog Synthetics, or CloudWatch Synthetics.
When it comes to chaos testing the tooling is usually modern, cloud-native and generally offers good DX, but tends to focus too much on infrastructure rather than applications. Applications are important because that’s how you get developers to care. Developers don’t want to care about infrastructure.
What the future looks like

To recap: most teams running production systems at scale are busy solving the reactive part of the puzzle. The next stage for the industry as a whole is looking at the proactive piece.
The tools for load testing, chaos testing, and synthetic testing are there, but they leave a lot to be desired. As production systems we run and rely on grow in complexity, the importance of those types of testing increases, and teams will be spending more time relying on those kinds of tests to keep everything running smoothly. To make these proactive tests easier to run we need tools that are modern, cloud-native, focus on developer experience, and can be offered as self-service platforms.
The FAANGs/MANGAs of the world are doing it all already, and many forward-looking teams at other companies are ahead of the curve and exploring what that’s going to look like for them, without all of the resources of a FAANG company to throw at it. The rest of the industry will follow in 2-3 years.
We can also go one step further, and ask ourselves: why have multiple tools for all this? Why can’t we have an all-in-one performance & reliability testing platform?
But I’ll leave that for another installment and wrap this up here as this write up is already long enough.
I’d love to hear your thoughts & comments! Hit me up on Twitter on @hveldstra or drop me an email on h@veldstra.org. I love talking all things performance testing, SRE and production engineering.
RSS